0
OCR Text Detection Tool
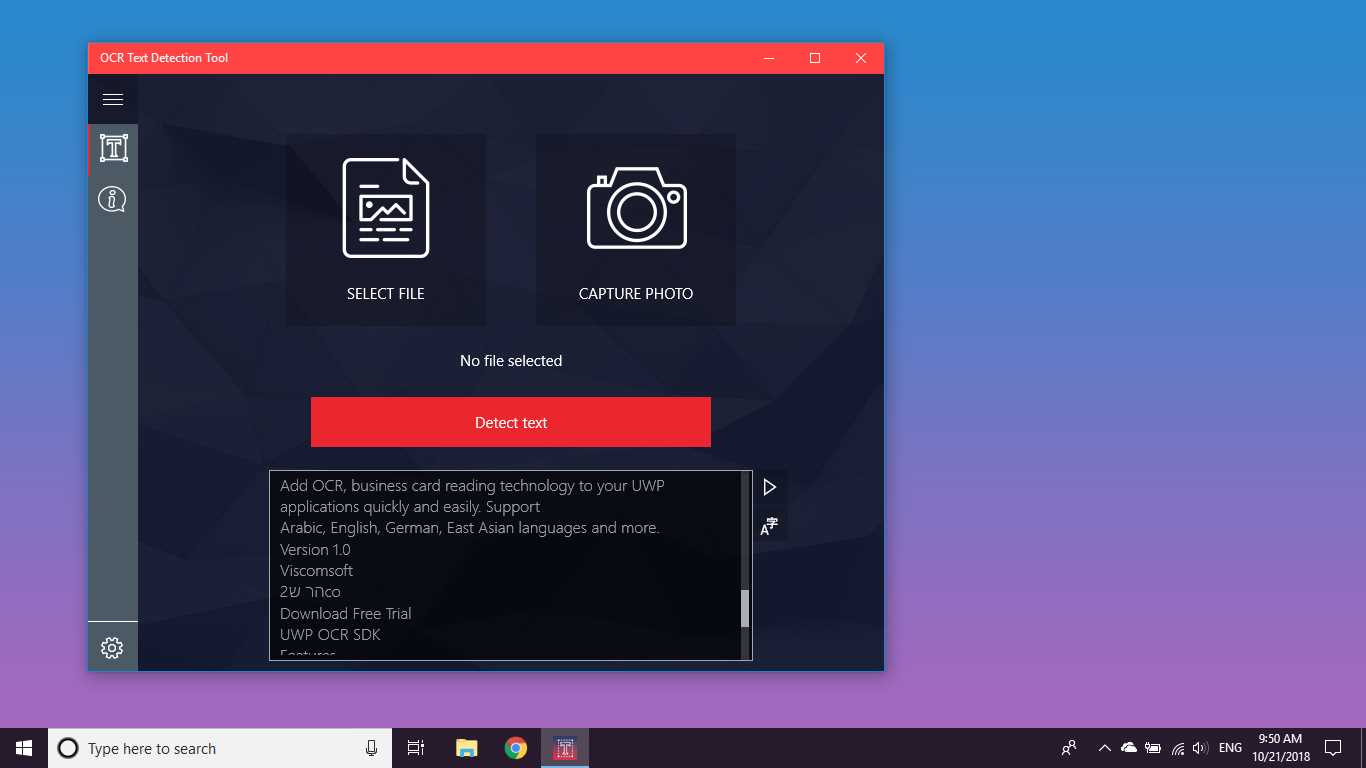
Cihazınızdan indirilen veya bir anlık görüntü ile çekilen herhangi bir görüntü dosyasından doğru ve hızlı metin algılama sağlar.Ayrıca PDF'nin metin algılanmasını ve 114 farklı dilde metin tabanlı el yazısı algılamasını ve metin çevirisini destekler.
- Ücretsiz
- Windows S
- Windows
- Windows Mobile
- Windows Phone
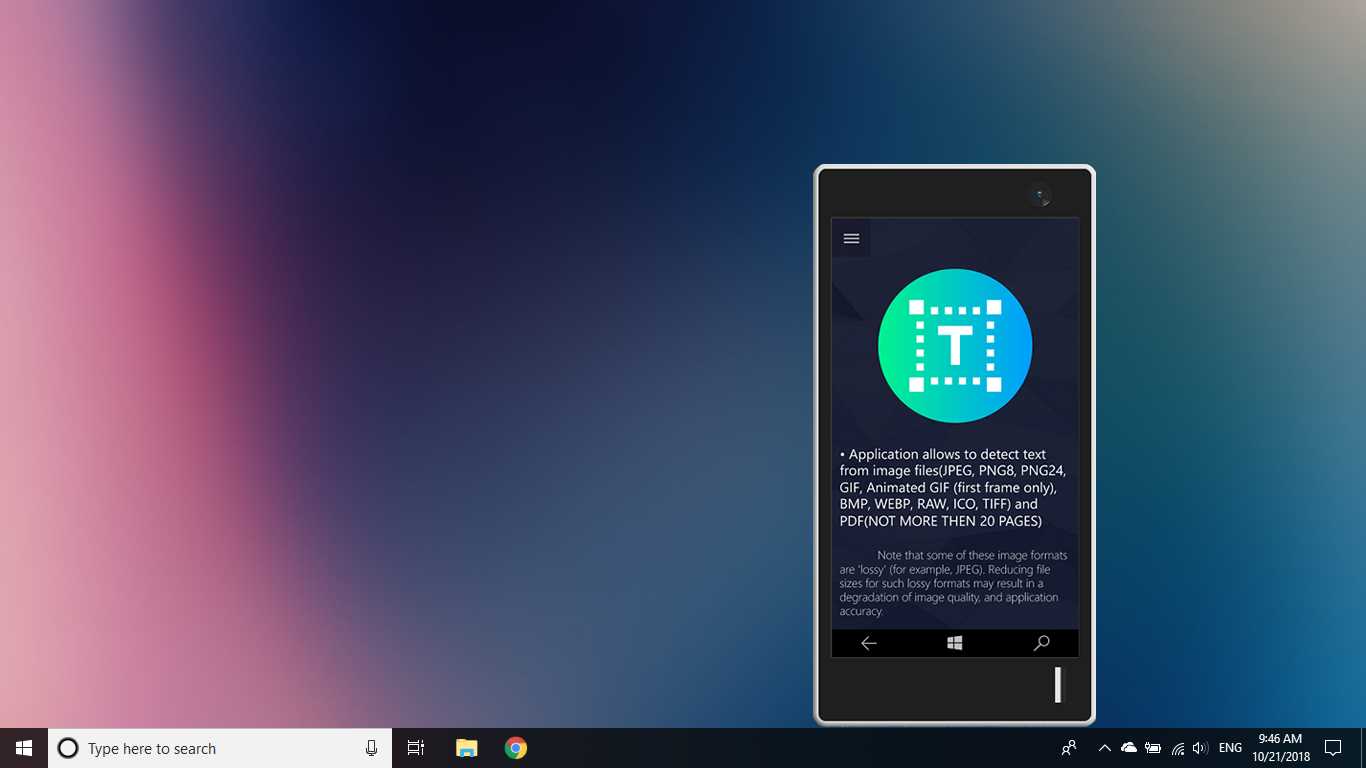
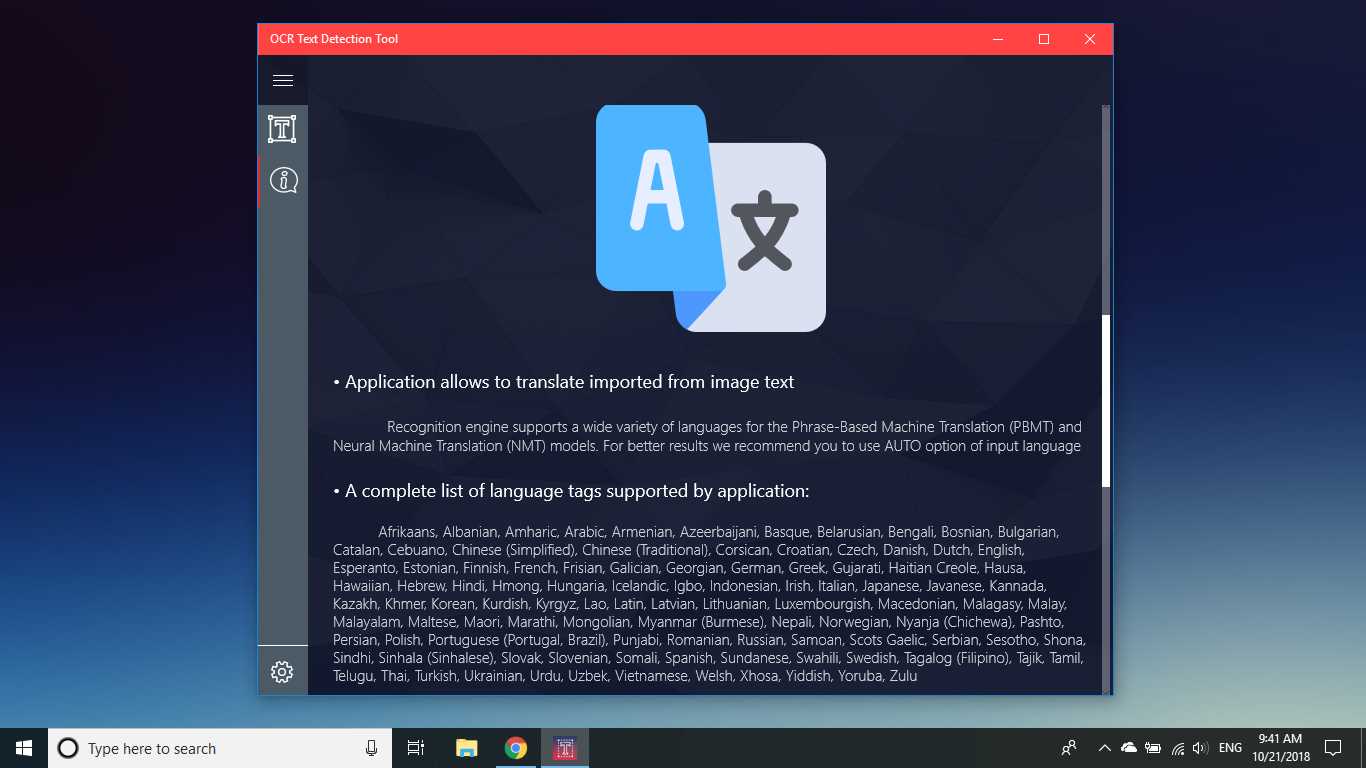
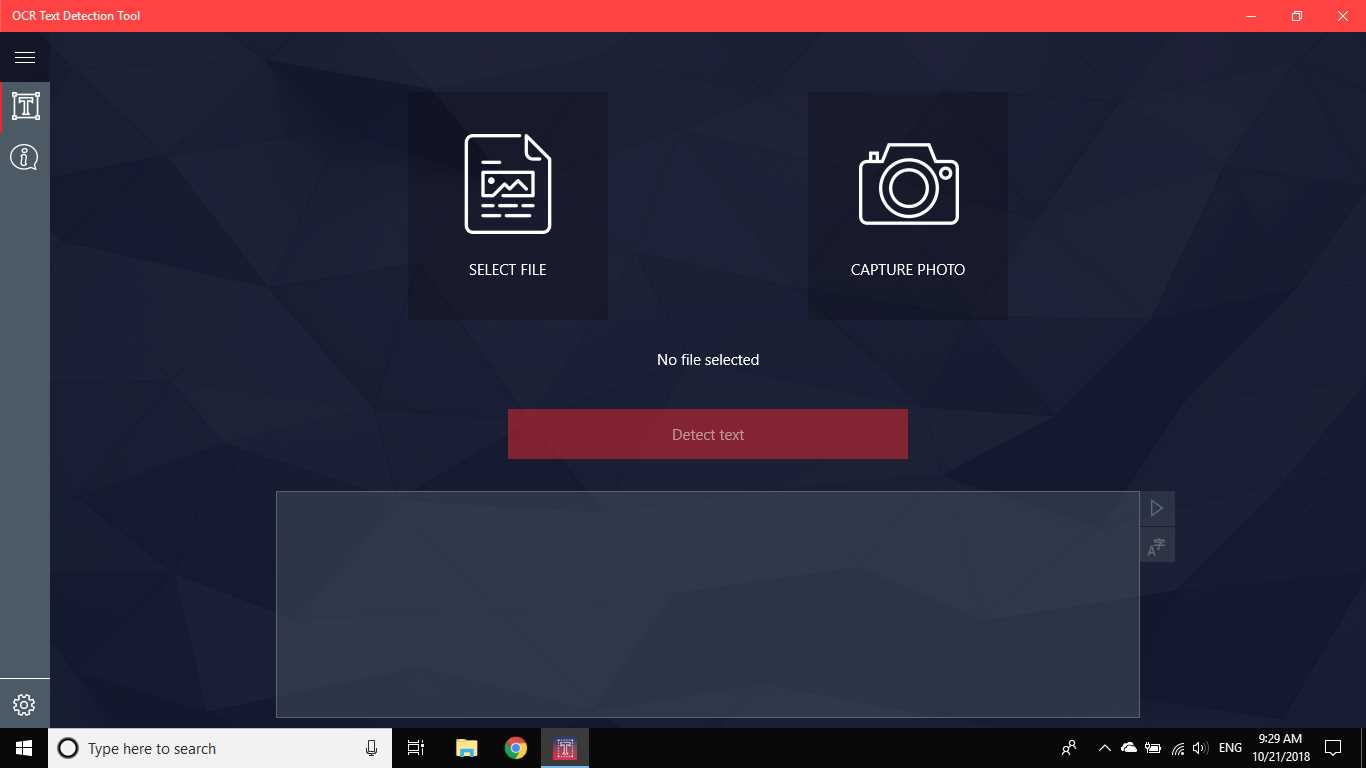
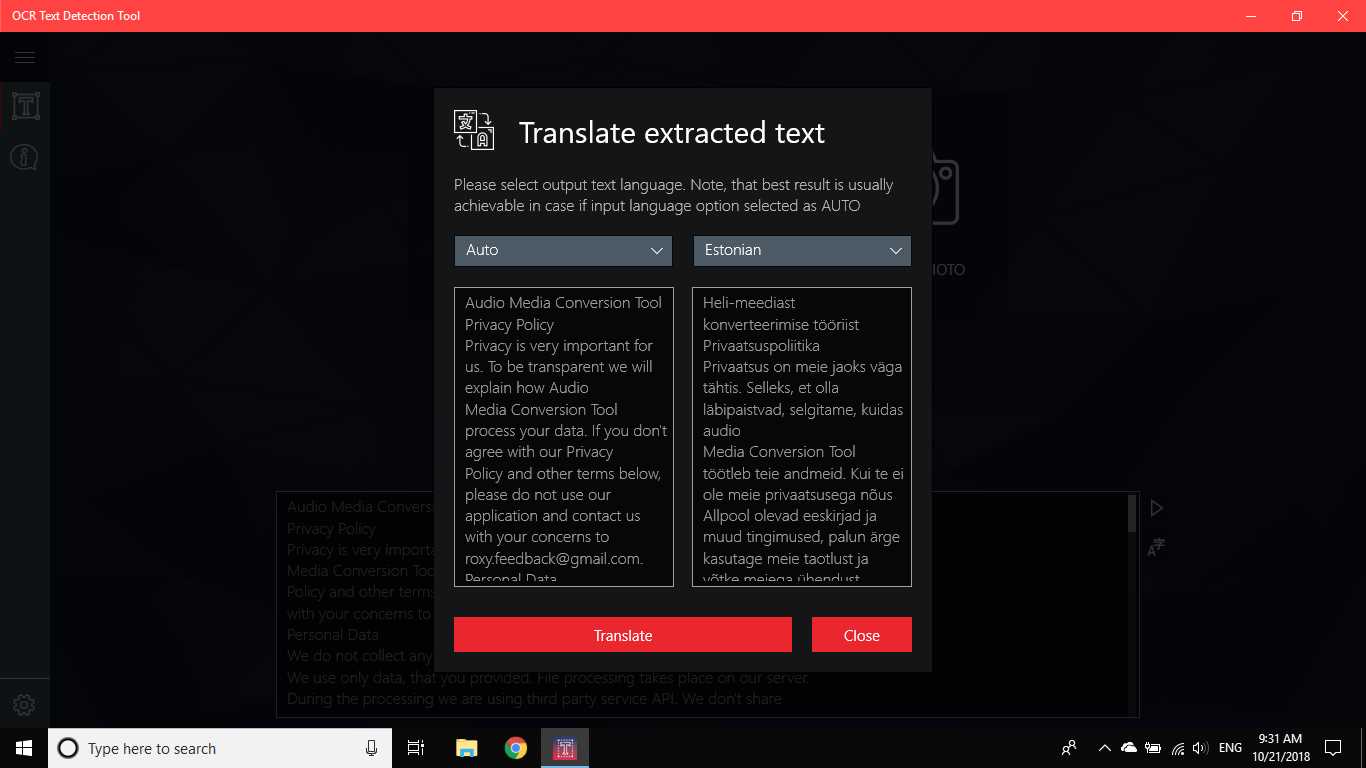
OCR Metin Algılama Aracı, cihazınızdan indirilen veya bir anlık görüntü ile çekilen herhangi bir görüntü dosyasından doğru ve hızlı metin algılama sağlar.Ayrıca bir PDF belgesinin metinsel olarak algılanmasını da destekler (şu anda 20 sayfadan fazla değil, ancak işlevselliği genişletmek için çalışıyoruz).Uygulama ayrıca 114 farklı dilde metin tabanlı el yazısı algılama ve metin çevirisini destekler.Dostu, net ve kullanışlı tasarım, uygulama ile çalışmayı kolay ve anlaşılır hale getirir.* Mevcut formatlar: JPEG, PNG8, PNG24, GIF, Animasyonlu GIF (yalnızca ilk kare), BMP, WEBP, RAW, ICO, TIFF, PDF (şu anda 20 sayfayı geçmiyor, ancak işlevselliği genişletmeye çalışıyoruz) * Metintanıma özelliği çok çeşitli dilleri algılayabilir ve tek bir görüntüde birden çok dili algılayabilir: Afrikaanca (af), Arapça (ar), Assamca (as), Azerice (az), Belarusça (be), Bengalce (bn), Bulgarca (bg), Katalanca (ca), Çince (zh *), Hırvatça (saat), Çekçe (cs), Danca (da), Hollandaca (nl), İngilizce (en), Estonca (et), Filipince (filveya tl), Fince (fi), Fransızca (fr), Almanca (de), Yunanca (el), İbranice (o veya iw), Hintçe (hi), Macarca (hu), İzlandaca (is), Endonezyaca (id), İtalyanca (it), Japonca (ja), Kazakça (kk), Korece (ko), Kırgızca (ky), Letonca (lv), Litvanca (lt), Makedonca (mk), Marathi (mr), Moğolca (mn), Nepalce (ne), Norveççe (no), Pashtu (ps), Farsça (fa), Lehçe (pl), Portekizce (pt), Rumence (ro), Rusça (ru), Sanskritçe (sa), Sırpça (sr), Slovakça (sk), Slovence (sl), İspanyolca (s), İsveççe (sv), Tamil (ta), Thai (th), Türkçe (tr), Ukraynaca (uk), Urduca (ur), Özbek (uz), Vietnamca (vi) Şuna bir bak, kaybedecek bir şeyin yok!
İnternet sitesi:
https://www.microsoft.com/store/apps/9PL1PPFPT8VJÖzellikleri
Kategoriler
Linux için OCR Text Detection Tool'a alternatifler
71
35
GImageReader
gImageReader Tesseract OCR Engine basit bir Gtk / Qt ön uçtur.Özellikler: - PDF belgeleri ve görüntüleri disk, tarama cihazları, pano ve ekran görüntüleri
9
8
5
5
4